How to separate the sheep from the goat using the Gini coefficient?
- Posted by LivingObjects
How to separate the sheep from the goat using the Gini coefficient?

Recognizing the sheep from the goat is a problem that our ancestors considered so important that they made it a proverb. Artificial Intelligence is now coming to our rescue to finally solve this dilemma.
The first question to ask when trying to understand the criteria that distinguish two sets of data:
“What are the features available to describe the objects considered?”
This is the most sensitive issue. For example, if you are trying to understand why the apricots you buy in July are sweeter than those you buy in May, and each apricot is described by the color of the price tag or the brand of the seller’s apron, you may not be able to answer the question.
In data mining, contrary to popular belief, it is better to have a hunch of where to search or you may not find anything.
In the afore mentioned example, if we add to the features: fruit color, variety, number of days of sunshine and location of the producer, we’ll hopefully have an answer. But with so many features, how do you identify the one with the most impact? As a customer, if I only had one question to ask in order to find the best fruit, should I ask about the sunshine duration or the variety?
The methods at our disposal in the field of Artificial Intelligence allow us to provide answers.
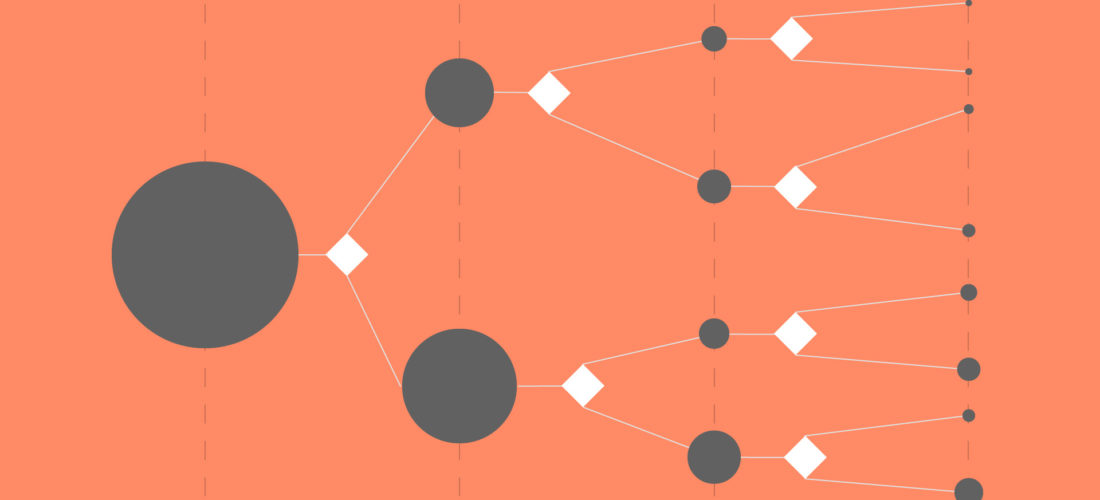
Decision trees
Decision trees allow you to graphically represent a succession of rules linked to each other. Their objective is to achieve classification, often represented by a binary separation.

This representation mode is used in “Expert Systems” approaches, where business expertise can be formalized into a succession of rules. But this is not always the case, and experience has shown that updating business rules is difficult over time.
When rules cannot be identified, an approach based on the analysis of observational data is used: the starting point is a known set of “objects”. Each object is described by features (e. g. color, origin and variety). Each feature may have several values (for example for color, the values may be green, yellow, orange). Finally, each object passes or fails a test (for example, apricot is sweet or not).
The objective is then to determine, from this control set, which are the feature values that allow to obtain sufficiently homogeneous groups, so that we can predict the test result for a new object. For example, if an apricot is green, regardless of the other attributes, it will certainly be found to belong to the “not sweet” class.
This is called “supervised learning” because the model has been trained from samples for which the test result is known in advance.
Decision trees are widely used for data mining or decision-making assistance:
- In data mining, they help understand and characterize better the handled objects or systems.
- When the decision rules are sufficiently clear-cut, they become diagnostic tools.
Decision trees also have another advantage over neural networks (at the present day, but much work is underway on this subject):
Decision trees are interpretable, meaning that a user can understand the process that led to the achieved model.
For large trees, the global model may be difficult to understand, but the classification on one node is always understandable.
The decision node
The question is to find an algorithm that allows, from a root node, to automatically separate a population of objects, by creating branches in an iterative way until reaching the leaves of the tree, i.e. consistent subgroups in which all the objects respond in the same way to a series of tests and hence belong to the same class. As long as a node contains objects that respond differently to the last test, the branching process continues.
All objects in an intermediate node or in a leaf are described by a unique conjunction of attribute conditions because the decision rules are mutually exclusive. For example, if the decision of a branch is taken according to the “orange” color (which is one of the possible values for the color feature), all the apricots of the first branch are orange and those of the other branch are either yellow or green but not orange.
The Entropy function and the Gini coefficient are two differentiation criteria that are frequently used to achieve separation. They are used to describe the homogeneity of a group of objects.
The Entropy function and the Gini coefficient are at their minimum when the group is totally homogeneous.
For each node, the objective is to find the feature and its corresponding values that best partition the group, i.e. the feature and the values that minimize the chosen separation index. As long as the group of objects contained in a node is not homogeneous, each node gives rise to two branches (binary trees) or several branches (n-ary trees). The most differentiating features are therefore the nearest to the tree root.
Breiman et al. (1984) formalized a methodology called CART (Classification And and Regression Tree) that generates binary trees using the Gini criterion as differentiating factor. This is the most common classification method.
The Gini index (optional reading)
The Gini index is a mathematical tool that measures the homogeneity of a population. It is used, for example, by statistical agencies to measure the distribution of wealth in a country.
In the CART method, it is used to measure the homogeneity of a set of objects for a given feature against a binary test. If we use our apricots again, we measure the Gini index for each of the features — color, origin and variety — according to the result of the test in two classes “sweet / not sweet”.
1st step, calculation of the Gini index
The Gini index is based on the variance for a set of objects responding to a test with two possible values, characteristic of Bernouilli’s law. Variance measures how far the data set is spread from its mean. It is defined as the expectation of the squares of deviations from the mean.
In the particular case of Bernouilli’s law, let p be the proportion of successful objects among all the objects considered, the variance is equal to
![]()
Let us consider a feature (ex: color) and its m possible values (ex: orange, green or yellow). For all Nm objects having one given value (i.e. green), whose test includes j choices or possible classes (sweet, not sweet, bitter), the Gini index is the sum of the variances for each class:

We will use this formula to measure the homogeneity of each set of objects defined by a feature/modality pair.
If the color feature has three possible values: green, orange and yellow, 3 indices will be calculated.
The lower the index, the more homogeneous the set. It is therefore likely that the index of the “color/green” couple is low or even zero if we assume that all green apricots aren’t sweet. But it is also likely that there are few green apricots for sale. It is therefore necessary to weight the value (green color in this case) index by the proportion of individuals to validate that color is a priority selection criterion.
This is the purpose of the second step of the calculation.
2nd step: Prioritizing attributes
For each attribute (e.g. color), let N be the total number of objects, Nm the number of individuals for the value m of the attribute (e. g. green) and im the Gini index for the same value, the Gini index for the feature is written:

First, the feature with the lowest index is chosen and then for this feature we select the value which also presents the lowest index. The node splits into two subgroups: one with the objects corresponding to the chosen feature/value and one with all the other objects. Then the operation is repeated on the two subgroups with the remaining feature/value pairs.
Does it work?
Well, it depends.
The quality of features is the key to success. Assuming that the sample size is sufficient for the system to “learn” correctly, there are still some pitfalls:
- If the separation does not depend on the features considered, nothing consistent will be found (e. g. feature = “Seller’s apron brand”)
- If a combination of conditions on the feature values (e. g. color = orange AND origin = Roussillon AND variety = Jumbocot) contains objects that respond differently to the test, a more or less acceptable margin of error may be obtained because of the leaf’s heterogeneity.
- If the situation evolves in time (for example, once in a while a new genetically engineered and improved variety of sweeter apricots appears), it will be necessary to provide for an update of the model at appropriate time points. Similarly, a new software upgrade for a specific board can totally challenge a predictive maintenance diagnostic model that was built under the previous software version.
However, in any case, decision trees have a powerful advantage over other methods such as neural networks: they allow the user to access the model explicitly. The user quickly visualizes if the data analysis makes sense and why it makes sense (or why it doesn’t).
To illustrate this point, let us take again the example of the feature “brand of the seller’s apron”. All sweet apricots may be sold by sellers dressed with the same apron (e.g. Fauchon) while other sellers from other stores have different aprons. This feature becomes the most important marker and appears first in the decision tree. It is up to the user to decide whether it is appropriate to leave it or remove it from the list of features. A strange feature that stands out as highly discriminating in a tree must always be interpreted before being rejected. The fact that the model is understandable allows the user to improve the tree and the decision algorithms.
The “expert system” and “observation analysis” approaches are complementary. They mutually benefit from each other to achieve the best of both worlds.
In practice, this means
In practice, shallow trees, with few iterations, will most often be considered. A deep tree is more difficult to understand and may be very dependent on the test set used to achieve learning. The extreme case is that of a model that only finds its relevance when the number of leaves equals the number of objects… This means that the model has not found a feature/value pair that allows homogeneous groups of more than one individual to be formed. It is obvious that adding new objects to the learning set will change the model. This is a classic learning problem, called overfitting: the model must be robust enough to support a change of the test set.
If the tree is deliberately stopped after a few iterations, some leaves may contain objects that are not totally homogeneous, i.e. they contain objects of several classes. However, the objective is not necessarily to have a 100% reliable decision but to support the decision with an acceptable error margin.
If a subgroup contains a large number of objects and if 95% of them are positive to the test, it can be assumed that the features characterizing the test are a good approximation of a successful test. For example, in predictive maintenance, it would not be economically interesting to send an engineer to replace a board if the probability of it to fail in the very near future is only of 50%. With a probability above 85% it would be totally relevant.
We are, therefore, trying to build a tree that is as small as possible with the tiniest error margin. A trade-off between performance on the train set and stability, i.e. the ability to generalize on unknown samples, will often have to be made. For two models with similar performance, it’s always better to choose the simplest one for predictive analysis.
Now that you are familiar with the most common classification model, let’s apply it to the recognition of sheep from the goat. The first question is:
“What are the available features to describe the objects considered?”
Not easy…….. welcome to the daily life of the data scientist.
References :
Breiman, Leo; Friedman, J. H.; Olshen, R. A.; Stone, C. J. (1984). Classification and regression trees. Monterey, CA: Wadsworth & Brooks/Cole Advanced Books & Software. ISBN 978-0-412-04841-8
0 comments on How to separate the sheep from the goat using the Gini coefficient?